
Can Mobile be the Birth of Great Customer Experiences?

I try not to be too sensitive, but after 25 years in the contact center industry, I still feel myself going on the defensive as friends and family regale me with their latest miserable customer service experience, or just ask me why in general it’s so bad most of the time. I cringe as studies reveal consumer dissatisfaction with a variety of industries and their service, or show that the perception of service measured through customer satisfaction lags far behind the internal view measured through quality monitoring scores. Where are the “Wow!” experiences we all seek?
We KNOW everyone is trying hard. The contact center industry has been on a long march with new engagement channels, innovative technology, improved processes, and better hiring and training techniques. People in our industry care and are passionate about service. Company after company talks about “transformation.” Unfortunately, few deliver.
While there are no “silver bullets,” we still think the smart money is on smartphones. Mobility has brought forth a sea change in how we communicate. As an industry, we need to do a better job of aligning ourselves with the changing tide.
Such Excitement and Opportunity
The statistics show the potential smartphones offer. For example, a Call Center Times survey from March 2013 states that 78% of respondents use mobile apps for customer service (billing, account status/updates, interactive chat), and 90% of respondents would replace some or all traditional customer service channels with a mobile app, if available. Those are compelling numbers.
Throw in a tablet as the new tool to take to a meeting, the coffee shop or your child’s sports event and you’ve got a complete set of indispensable tools that free you from so many restrictions. Our love affair with mobile devices perhaps belongs in the ranks of the light bulb, telephone, car, TV, PC and Internet for transformational technologies. The mobile opportunity springs from an incredibly impactful and ubiquitous tool for the customer base of most companies.
We’re all on the go, using these devices non-stop. We need “timely” communication. These days, timely has a new urgency for even the most mundane interactions. We purchase, consume and seek information and service in ways we never used to. Like to read a book, magazine or newspaper? You do so without touching a piece of paper. Want to watch a video, rock out to some music, or listen to a lecture? Who needs a TV, radio, CD, DVD or classroom? Need to deposit a check or file an insurance claim or check in for a flight? You need not bother with a branch, agent or kiosk. Our approach to these everyday tasks has truly been transformed. Personally and professionally, whatever your age or “generation,” things will never be the same. But what about customer interactions with the contact center?
Where’s the Change?
We’ve written about mobile’s potential in the contact center as recently as November 2012 (“Mobile and the Contact Center: The Game Is Changing,” Pipeline). Many organizations have attempted to capitalize on the opportunity. But our family and friends have experienced a brick wall when their highly versatile mobile devices prove to be no better than a landline when they need to talk to someone, or get some more personalized, specific help.
We went in search of “success stories” and felt a bit like Yukon Cornelius throwing his pick in the air and checking for gold when it lands: “Nothing.” Whether mobile app integration with the center or cross-channel integration, we’re coming up short. We dug deep into our own mobile apps with banks, airlines, hotels, retailers and more, looking for true links to customer interaction that would engage talented contact center staff in helping address questions and issues. Nothing. Hype and happenings seem to be out of step. Why so little traction?
Vendors Are Trying
It is not for lack of trying from vendors. As our previous article shows, there are plentiful product offerings in a variety of flavors. But when approaching prospects, some vendors couldn’t get to the right buyers, or the prospects simply weren’t ready. “Not ready” can manifest as a defensive posture that “customers don’t want to download mobile apps,” few mobile apps lead to ongoing use, or a claim that mobile apps are about self service, mirroring the web world, not about getting to a contact center. And some companies don’t want to facilitate customer access to the center anyway (because after all, that costs more than a self service interaction). Some even try to direct the customer to FAQs instead of getting to a person. Perhaps as a result of this experience, the main messaging from vendors seems to have changed from a focus on mobile applications themselves to the full customer experience and integration across channels. But these platitudes don’t lead to transformation.
Some of the vendors in OUR industry, with a contact center focus, have resorted to faking out the IVR as a more likely scenario. It’s easier to make happen, more often in the contact center’s control, and more in line with the center’s goals and role. Taking a contact triggered from a mobile device, it’s relatively easy to route the customer to the right place with information they’ve already entered from the application, or can readily enter through a better interface (visual) than the IVR. The mobile interface is user friendly, and the application transforms entries from that interface into tones the existing IVR can use.
Technology is not the issue here. These mobile integration capabilities can leverage other existing contact center technology successes. In addition to leveraging the IVR capabilities, they can be CTI and CRM-like in using data and information about the customer. They can tie into call-back queues, which many companies and customers are fans of these days. They can tie into knowledge bases or wikis to tap broader sources of knowledge. And they can even cross channels with things like SMS/text, social and outbound notifications.
It’s a Silo Thing
Unfortunately, in spite of all its potential, mobile faces some of the same challenges other channels do: diverse departmental ownership and too many projects vying for the attention of too few resources, budget dollars and days on the calendar. Our multimedia studies have shown mobile is typically owned by IT or marketing, not the contact center (see “Companies Dive Deeper into Multichannel Customer Contact,” Pipeline, March 2012). So while vendors may tout the “customer experience” and lump mobile into this broader goal, I have a sneaking suspicion based on our project work that the likelihood of various channel owners (departments) coming together to build a cohesive multichannel strategy and ensure effective cross-channel customer experiences is low. It’s a rare company that has the level of customer focus, engagement across leaders, and ability to bring the resources together and prioritize to pull that off. But it’s possible (see “Multichannel Technology Comes into Its Own,” Pipeline, February 2012).
I think the focus of limited resources (people, time and money) is on solving fundamental issues first, such as: replacing old technology for the high percentage of contacts that are “voice” (meaning traditional voice contacts not leveraging mobile capabilities), fighting daily fires on the frontline, and trying to find ways to cut costs, drive revenue and/or improve service. But wait a minute, that’s exactly what mobile could help centers achieve!
Real Opportunity Requires Real Action
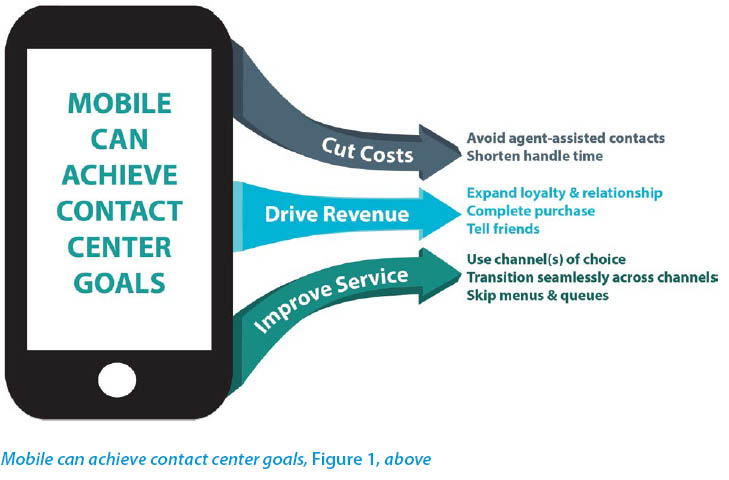
Yes, a good mobile app, integrated with the contact center, can achieve one or more of the “holy grail” goals of centers:
Cut costs: Every agent contact avoided because someone self-serves on a mobile app saves dollars. Every time information is passed from a mobile device to the agent to aid in identification and verification, handle time and, therefore, cost goes down.
Drive revenue: A customer who becomes a fan of the mobile app and knows they can get help when needed views the company as truly “easy to do business with.” That means they stay a loyal customer, potentially buy more or otherwise expand their relationship with the company, and may even tell their friends (one on one or through their social media ravings). At the micro level, assistance may help them complete a purchase that they otherwise would have abandoned. Ka-ching!
Improve service: As I mentioned at the start of the article, there is plenty of room for improvement in the service experience. A customer who can use the device and channel(s) of choice and know they will succeed every time may sing a different tune than the typical ones who feel like there is no connection between channels. Someone who avoids queues and menus may be truly “wowed” by the service. It’s all possible.
It’s time to lift our heads and tackle the challenges of customer experience and join the transformational world. This will require a cross-organizational team with marketing, eCommerce and IT, at least. This issue is not really all about the technology or the vendors, and it’s certainly not all about the contact center. But we can and must be a catalyst to leverage the potential of this transformational tool and its ability to link into the people, processes and technology that are ready, willing and able to help. When we succeed, we should promote it like crazy, because it’s time for customer care to get some respect.
Then perhaps next time I seek an update on the state of customer care and the impact mobile devices have had, I will find a different outcome. I envision the next family gathering or college reunion I attend, where my friends and family will regale me with stories about their really cool mobile apps and how they have connected with really helpful people—easily and seamlessly. And I will joyfully reply, “Wow!”
Lori Bocklund is Founder and President of Strategic Contact. lori@strategiccontact.com



